If you weren't able to make @everythingopen in Adelaide in January but were still keen to catch my talk on the #TokenWars in #ML - the hunt for real, human data amidst a sea of AI-generated slop - then don't despair!
I'm delighted to be giving this talk again at the Melbourne ML and AI meetup in mid-April - with thanks to Lizzie Silver for the behind the scenes organisation and to Jonathan Oxer for making the connection.
Seats are strictly limited - so sign up as soon as you can!
 Tuesday 15th April, 6pm to 8pm AEST
Tuesday 15th April, 6pm to 8pm AEST
 Docklands Hub, next to Library at the Dock, 912 Collins Street, Melbourne
Docklands Hub, next to Library at the Dock, 912 Collins Street, Melbourne
Talk Title: The Token Wars: why not all our content should be open
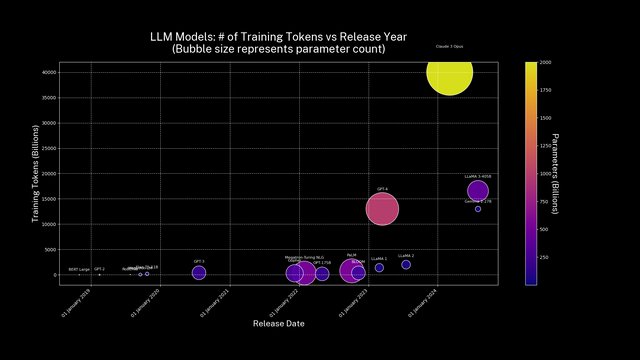
Abstract: In recent years, there has been an explosion in generative AI. Most of us are now familiar with tools like ChatGPT, Midjourney, Sora, and others. At the heart of generative AI is a machine learning architecture called the "transformer", which is fed by huge datasets - text, images and videos. Those datasets are "tokenised" - cut up into chunks which the transformer can ingest. Those actors who can obtain the most tokens can generally train the best models (for various values of "best").
We are now witnessing a battle between the creators of generative AI models - who seek to obtain as much data as possible for tokenisation - while their targets try to stop them. The social ramifications of this resource conflict are widespread, resulting in "alateral damage" - a term I am coining to point to the unforeseen, unintended, distal consequences of a seemingly innocuous technology.
These are the Token Wars.
And they're the reason not all our content should be openly available.
In this three-part talk, I first provide a technical grounding on transformers, tokens and how they're used to build text-based generative AI. In the second part, I draw on economics to ask, "why are tokens so valuable?", showing that as the internet becomes filled with AI slop, human-created data is becoming more scarce - and so more expensive. In the third part I explore how you might approach guarding your token treasure, from data poisoning to alternative licensing models and data sovereignty.
You'll leave this talk never looking at data or ChatGPT the same way again.
https://www.meetup.com/machine-learning-ai-meetup/events/306548300/?utm_medium=referral&utm_campaign=share-btn_savedevents_share_modal&utm_source=link