Replied in thread

"Für den eGovernment Podcast von Torsten Frenzel habe ich einige Begriffe rund um #AI #KI erklärt, beispielsweise warum mehrere aktuelle Studien u.a. von #goldmansachs vor #PeakAI warnen, was #slop, #autophagy, #enshitification und #modelcollapse sind und warum wir dem gerade zuschauen. Abermilliarden werden da gerade investiert, Zerstörung des Klimas inbegriffen (aber das war hier gar nicht Thema). Ansonsten ging's ums Zentrum Digitale Souveränität (ZenDiS)...."
https://www.linkedin.com/posts/markusfeilner_monatsschau-0824-activity-7235961839652601856-Log9

www.linkedin.comFür den eGovernment Podcast von Torsten Frenzel habe ich einige Begriffe rund um #AI #KI erklärt, beispielsweise warum mehrere aktuelle Studien u.a. | Markus FeilnerFür den eGovernment Podcast von Torsten Frenzel habe ich einige Begriffe rund um #AI #KI erklärt, beispielsweise warum mehrere aktuelle Studien u.a. von #goldmansachs vor #PeakAI warnen, was #slop, #autophagy, #enshitification und #modelcollapse sind und warum wir dem gerade zuschauen. Abermilliarden werden da gerade investiert, Zerstörung des Klimas inbegriffen (aber das war hier gar nicht Thema). Ansonsten ging's ums Zentrum Digitale Souveränität (ZenDiS) und ein Kudo für den scheidenden Andreas Reckert-Lodde, #opendesk und B1 Systems und mehr. Anhören!
https://lnkd.in/duCC8xWz












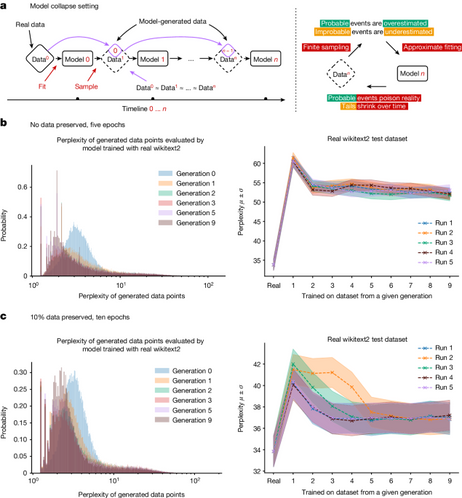
 Model collapse: when AI systems trained on synthetic content begin degrading like photocopies of photocopies. Recent experiments show recursive training leads to semantic drift and loss of signal—errors accumulate slowly, precision decays steadily.
Model collapse: when AI systems trained on synthetic content begin degrading like photocopies of photocopies. Recent experiments show recursive training leads to semantic drift and loss of signal—errors accumulate slowly, precision decays steadily. The real risk isn't technical fragility but institutional misalignment. When knowledge production prioritizes scale over truth, collapse becomes symptom of concentrated power.
The real risk isn't technical fragility but institutional misalignment. When knowledge production prioritizes scale over truth, collapse becomes symptom of concentrated power.